Note
Go to the end to download the full example code.
Quick Visualization for Hyperparameter Optimization Analysis
Optuna provides various visualization features in optuna.visualization to analyze optimization results visually.
Note that this tutorial requires Plotly to be installed:
$ pip install plotly
# Required if you are running this tutorial in Jupyter Notebook.
$ pip install nbformat
If you prefer to use Matplotlib instead of Plotly, please run the following command:
$ pip install matplotlib
This tutorial walks you through this module by visualizing the optimization results of PyTorch model for FashionMNIST dataset.
For visualizing multi-objective optimization (i.e., the usage of optuna.visualization.plot_pareto_front()),
please refer to the tutorial of Multi-objective Optimization with Optuna.
Note
By using Optuna Dashboard, you can also check the optimization history, hyperparameter importances, hyperparameter relationships, etc. in graphs and tables. Please make your study persistent using RDB backend and execute following commands to run Optuna Dashboard.
$ pip install optuna-dashboard
$ optuna-dashboard sqlite:///example-study.db
Please check out the GitHub repository for more details.
Manage Studies |
Visualize with Interactive Graphs |
|---|---|
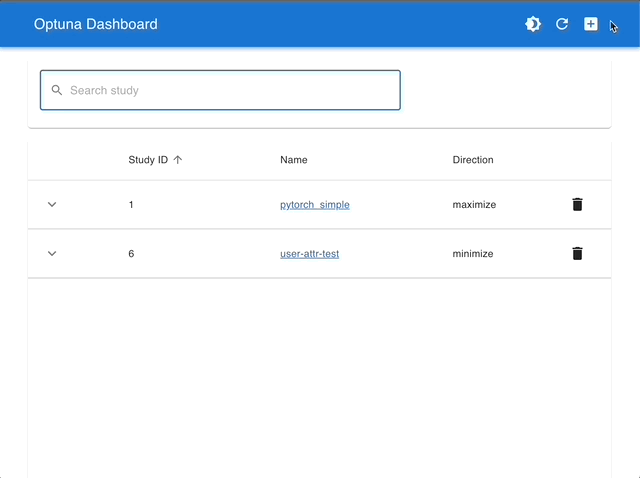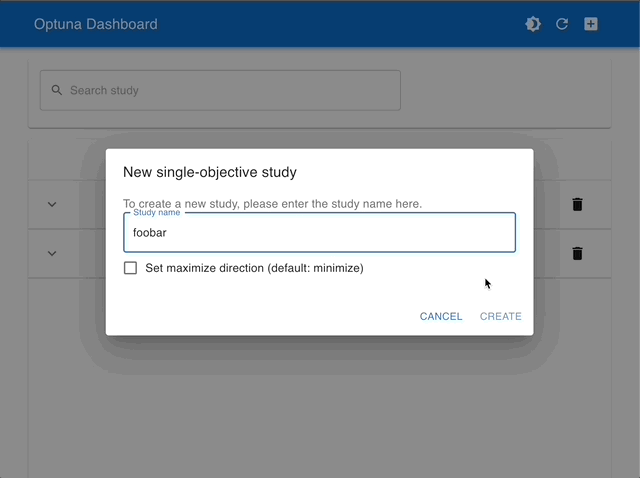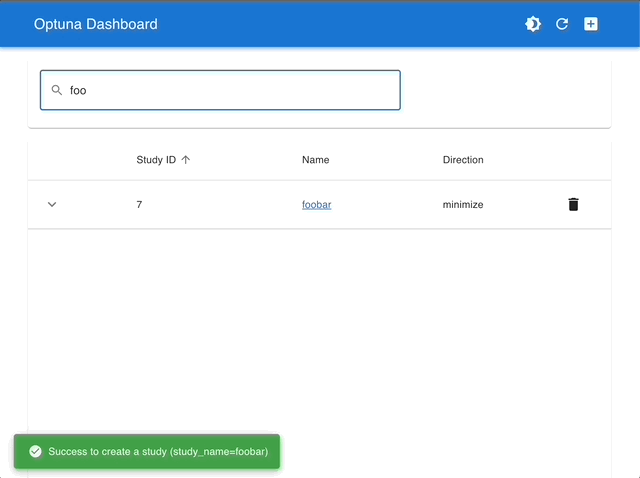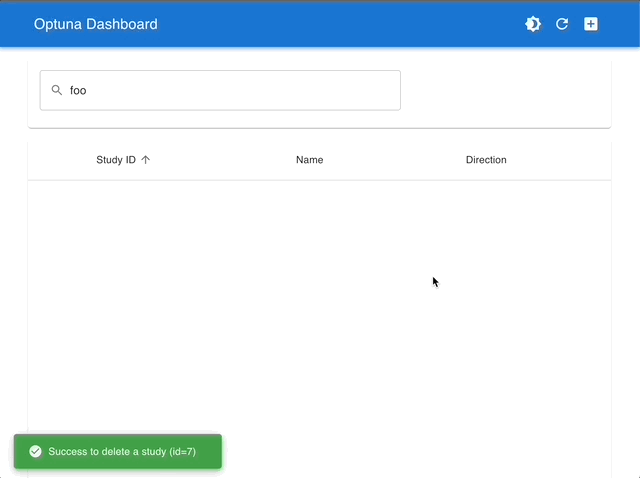
|
|
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import optuna
# You can use Matplotlib instead of Plotly for visualization by simply replacing `optuna.visualization` with
# `optuna.visualization.matplotlib` in the following examples.
from optuna.visualization import plot_contour
from optuna.visualization import plot_edf
from optuna.visualization import plot_intermediate_values
from optuna.visualization import plot_optimization_history
from optuna.visualization import plot_parallel_coordinate
from optuna.visualization import plot_param_importances
from optuna.visualization import plot_rank
from optuna.visualization import plot_slice
from optuna.visualization import plot_timeline
SEED = 13
torch.manual_seed(SEED)
DEVICE = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
DIR = ".."
BATCHSIZE = 128
N_TRAIN_EXAMPLES = BATCHSIZE * 30
N_VALID_EXAMPLES = BATCHSIZE * 10
def define_model(trial):
n_layers = trial.suggest_int("n_layers", 1, 2)
layers = []
in_features = 28 * 28
for i in range(n_layers):
out_features = trial.suggest_int(f"n_units_l{i}", 64, 512)
layers.append(nn.Linear(in_features, out_features))
layers.append(nn.ReLU())
in_features = out_features
layers.append(nn.Linear(in_features, 10))
layers.append(nn.LogSoftmax(dim=1))
return nn.Sequential(*layers)
# Defines training and evaluation.
def train_model(model, optimizer, train_loader):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.view(-1, 28 * 28).to(DEVICE), target.to(DEVICE)
optimizer.zero_grad()
F.nll_loss(model(data), target).backward()
optimizer.step()
def eval_model(model, valid_loader):
model.eval()
correct = 0
with torch.no_grad():
for batch_idx, (data, target) in enumerate(valid_loader):
data, target = data.view(-1, 28 * 28).to(DEVICE), target.to(DEVICE)
pred = model(data).argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
accuracy = correct / N_VALID_EXAMPLES
return accuracy
Define the objective function.
def objective(trial):
train_dataset = torchvision.datasets.FashionMNIST(
DIR, train=True, download=True, transform=torchvision.transforms.ToTensor()
)
train_loader = torch.utils.data.DataLoader(
torch.utils.data.Subset(train_dataset, list(range(N_TRAIN_EXAMPLES))),
batch_size=BATCHSIZE,
shuffle=True,
)
val_dataset = torchvision.datasets.FashionMNIST(
DIR, train=False, transform=torchvision.transforms.ToTensor()
)
val_loader = torch.utils.data.DataLoader(
torch.utils.data.Subset(val_dataset, list(range(N_VALID_EXAMPLES))),
batch_size=BATCHSIZE,
shuffle=True,
)
model = define_model(trial).to(DEVICE)
optimizer = torch.optim.Adam(
model.parameters(), trial.suggest_float("lr", 1e-5, 1e-1, log=True)
)
for epoch in range(10):
train_model(model, optimizer, train_loader)
val_accuracy = eval_model(model, val_loader)
trial.report(val_accuracy, epoch)
if trial.should_prune():
raise optuna.exceptions.TrialPruned()
return val_accuracy
study = optuna.create_study(
direction="maximize",
sampler=optuna.samplers.TPESampler(seed=SEED),
pruner=optuna.pruners.MedianPruner(),
)
study.optimize(objective, n_trials=30, timeout=300)
0%| | 0.00/26.4M [00:00<?, ?B/s]
0%| | 65.5k/26.4M [00:00<01:19, 330kB/s]
1%| | 197k/26.4M [00:00<00:35, 741kB/s]
1%|▏ | 360k/26.4M [00:00<00:24, 1.08MB/s]
3%|▎ | 819k/26.4M [00:00<00:11, 2.30MB/s]
6%|▋ | 1.67M/26.4M [00:00<00:05, 4.36MB/s]
12%|█▏ | 3.24M/26.4M [00:00<00:02, 8.02MB/s]
22%|██▏ | 5.73M/26.4M [00:00<00:01, 13.3MB/s]
32%|███▏ | 8.52M/26.4M [00:00<00:01, 17.8MB/s]
43%|████▎ | 11.4M/26.4M [00:00<00:00, 21.3MB/s]
58%|█████▊ | 15.2M/26.4M [00:01<00:00, 26.3MB/s]
73%|███████▎ | 19.4M/26.4M [00:01<00:00, 30.7MB/s]
89%|████████▊ | 23.4M/26.4M [00:01<00:00, 33.5MB/s]
100%|██████████| 26.4M/26.4M [00:01<00:00, 20.1MB/s]
0%| | 0.00/29.5k [00:00<?, ?B/s]
100%|██████████| 29.5k/29.5k [00:00<00:00, 290kB/s]
100%|██████████| 29.5k/29.5k [00:00<00:00, 289kB/s]
0%| | 0.00/4.42M [00:00<?, ?B/s]
1%| | 32.8k/4.42M [00:00<00:13, 318kB/s]
1%|▏ | 65.5k/4.42M [00:00<00:13, 317kB/s]
3%|▎ | 131k/4.42M [00:00<00:09, 462kB/s]
5%|▌ | 229k/4.42M [00:00<00:06, 656kB/s]
10%|█ | 459k/4.42M [00:00<00:03, 1.22MB/s]
21%|██ | 918k/4.42M [00:00<00:01, 2.31MB/s]
41%|████▏ | 1.84M/4.42M [00:00<00:00, 4.46MB/s]
83%|████████▎ | 3.67M/4.42M [00:00<00:00, 8.69MB/s]
100%|██████████| 4.42M/4.42M [00:00<00:00, 5.34MB/s]
0%| | 0.00/5.15k [00:00<?, ?B/s]
100%|██████████| 5.15k/5.15k [00:00<00:00, 36.4MB/s]
Plot functions
Visualize the optimization history. See plot_optimization_history() for the details.
plot_optimization_history(study)
Visualize the learning curves of the trials. See plot_intermediate_values() for the details.
plot_intermediate_values(study)
Visualize high-dimensional parameter relationships. See plot_parallel_coordinate() for the details.
plot_parallel_coordinate(study)
Select parameters to visualize.
plot_parallel_coordinate(study, params=["lr", "n_layers"])
Visualize hyperparameter relationships. See plot_contour() for the details.
plot_contour(study)
Select parameters to visualize.
plot_contour(study, params=["lr", "n_layers"])
Visualize individual hyperparameters as slice plot. See plot_slice() for the details.
plot_slice(study)
Select parameters to visualize.
plot_slice(study, params=["lr", "n_layers"])
Visualize parameter importances. See plot_param_importances() for the details.
plot_param_importances(study)
Learn which hyperparameters are affecting the trial duration with hyperparameter importance.
optuna.visualization.plot_param_importances(
study, target=lambda t: t.duration.total_seconds(), target_name="duration"
)
Visualize empirical distribution function. See plot_edf() for the details.
plot_edf(study)
Visualize parameter relations with scatter plots colored by objective values. See plot_rank() for the details.
plot_rank(study)
Visualize the optimization timeline of performed trials. See plot_timeline() for the details.
plot_timeline(study)
Customize generated figures
In optuna.visualization and optuna.visualization.matplotlib, a function returns an editable figure object:
plotly.graph_objects.Figure or matplotlib.axes.Axes depending on the module.
This allows users to modify the generated figure for their demand by using API of the visualization library.
The following example replaces figure titles drawn by Plotly-based plot_intermediate_values() manually.
fig = plot_intermediate_values(study)
fig.update_layout(
title="Hyperparameter optimization for FashionMNIST classification",
xaxis_title="Epoch",
yaxis_title="Validation Accuracy",
)
Total running time of the script: (2 minutes 13.593 seconds)