![]()
Optuna: A hyperparameter optimization framework
Optuna is an automatic hyperparameter optimization software framework, particularly designed for machine learning. It features an imperative, define-by-run style user API. Thanks to our define-by-run API, the code written with Optuna enjoys high modularity, and the user of Optuna can dynamically construct the search spaces for the hyperparameters.
Key Features
Optuna has modern functionalities as follows:
Lightweight, versatile, and platform agnostic architecture
Handle a wide variety of tasks with a simple installation that has few requirements.
-
Define search spaces using familiar Python syntax including conditionals and loops.
Efficient optimization algorithms
Adopt state-of-the-art algorithms for sampling hyperparameters and efficiently pruning unpromising trials.
-
Scale studies to tens or hundreds of workers with little or no changes to the code.
-
Inspect optimization histories from a variety of plotting functions.
Basic Concepts
We use the terms study and trial as follows:
Study: optimization based on an objective function
Trial: a single execution of the objective function
Please refer to sample code below. The goal of a study is to find out
the optimal set of hyperparameter values (e.g., classifier and
svm_c) through multiple trials (e.g., n_trials=100). Optuna is
a framework designed for the automation and the acceleration of the
optimization studies.
![]()
import ...
# Define an objective function to be minimized.
def objective(trial):
# Invoke suggest methods of a Trial object to generate hyperparameters.
regressor_name = trial.suggest_categorical('classifier', ['SVR', 'RandomForest'])
if regressor_name == 'SVR':
svr_c = trial.suggest_float('svr_c', 1e-10, 1e10, log=True)
regressor_obj = sklearn.svm.SVR(C=svr_c)
else:
rf_max_depth = trial.suggest_int('rf_max_depth', 2, 32)
regressor_obj = sklearn.ensemble.RandomForestRegressor(max_depth=rf_max_depth)
X, y = sklearn.datasets.fetch_california_housing(return_X_y=True)
X_train, X_val, y_train, y_val = sklearn.model_selection.train_test_split(X, y, random_state=0)
regressor_obj.fit(X_train, y_train)
y_pred = regressor_obj.predict(X_val)
error = sklearn.metrics.mean_squared_error(y_val, y_pred)
return error # An objective value linked with the Trial object.
study = optuna.create_study() # Create a new study.
study.optimize(objective, n_trials=100) # Invoke optimization of the objective function.
Web Dashboard
Optuna Dashboard is a real-time web dashboard for Optuna. You can check the optimization history, hyperparameter importance, etc. in graphs and tables. You don’t need to create a Python script to call Optuna’s visualization functions. Feature requests and bug reports are welcome!
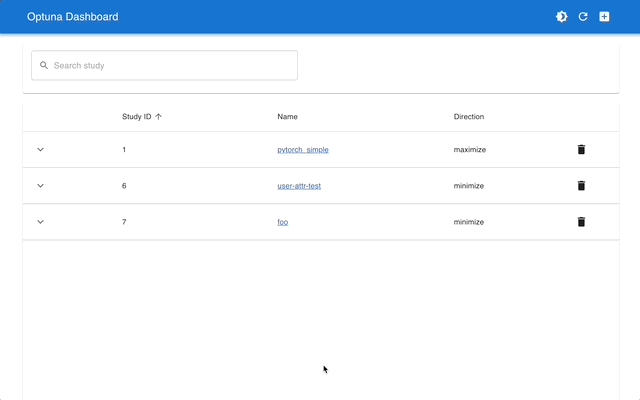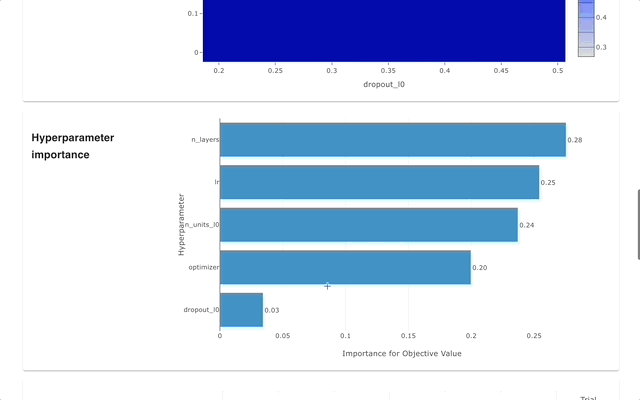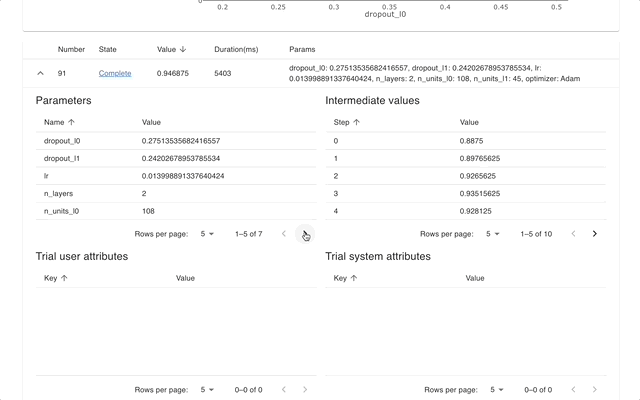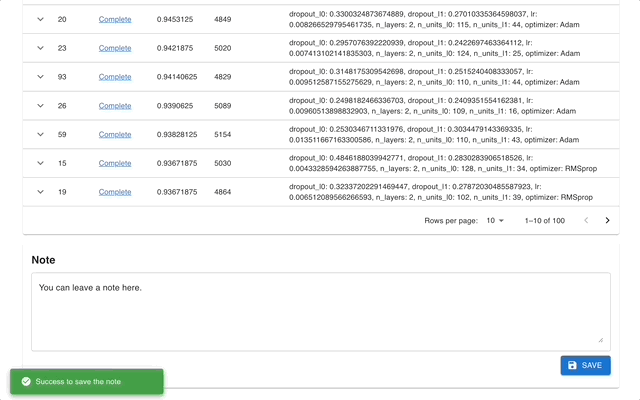
optuna-dashboard can be installed via pip:
$ pip install optuna-dashboard
Tip
Please check out the getting started section of Optuna Dashboard’s official documentation.
OptunaHub
OptunaHub is a feature-sharing platform for Optuna. You can use the registered features and publish your packages. For more details, please refer to the official documentation.

optunahub can be installed via pip:
$ pip install optunahub
Communication
GitHub Discussions for questions.
GitHub Issues for bug reports and feature requests.
Contribution
Any contributions to Optuna are welcome! When you send a pull request, please follow the contribution guide.
License
MIT License (see LICENSE).
Optuna uses the codes from SciPy and fdlibm projects (see Third-party License).
Reference
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. 2019. Optuna: A Next-generation Hyperparameter Optimization Framework. In KDD (arXiv).
Contents:
- Installation
- Tutorial
- API Reference
- FAQ
- Can I use Optuna with X? (where X is your favorite ML library)
- How to define objective functions that have own arguments?
- Can I use Optuna without remote RDB servers?
- How can I save and resume studies?
- How to suppress log messages of Optuna?
- How to save machine learning models trained in objective functions?
- How can I obtain reproducible optimization results?
- How are exceptions from trials handled?
- How are NaNs returned by trials handled?
- What happens when I dynamically alter a search space?
- How can I use two GPUs for evaluating two trials simultaneously?
- How can I test my objective functions?
- How do I avoid running out of memory (OOM) when optimizing studies?
- How can I output a log only when the best value is updated?
- How do I suggest variables which represent the proportion, that is, are in accordance with Dirichlet distribution?
- How can I optimize a model with some constraints?
- How can I parallelize optimization?
- How can I solve the error that occurs when performing parallel optimization with SQLite3?
- Can I monitor trials and make them failed automatically when they are killed unexpectedly?
- How can I deal with permutation as a parameter?
- How can I ignore duplicated samples?
- How can I delete all the artifacts uploaded to a study?
- Can I specify parameter starting points before optimization?
- How can I resolve case sensitivity issues with MySQL?